Prerequisite
1. In All Guidewire xCenters import sample data
2. Create account in Databricks Community edition, In this edition Databricks is Free
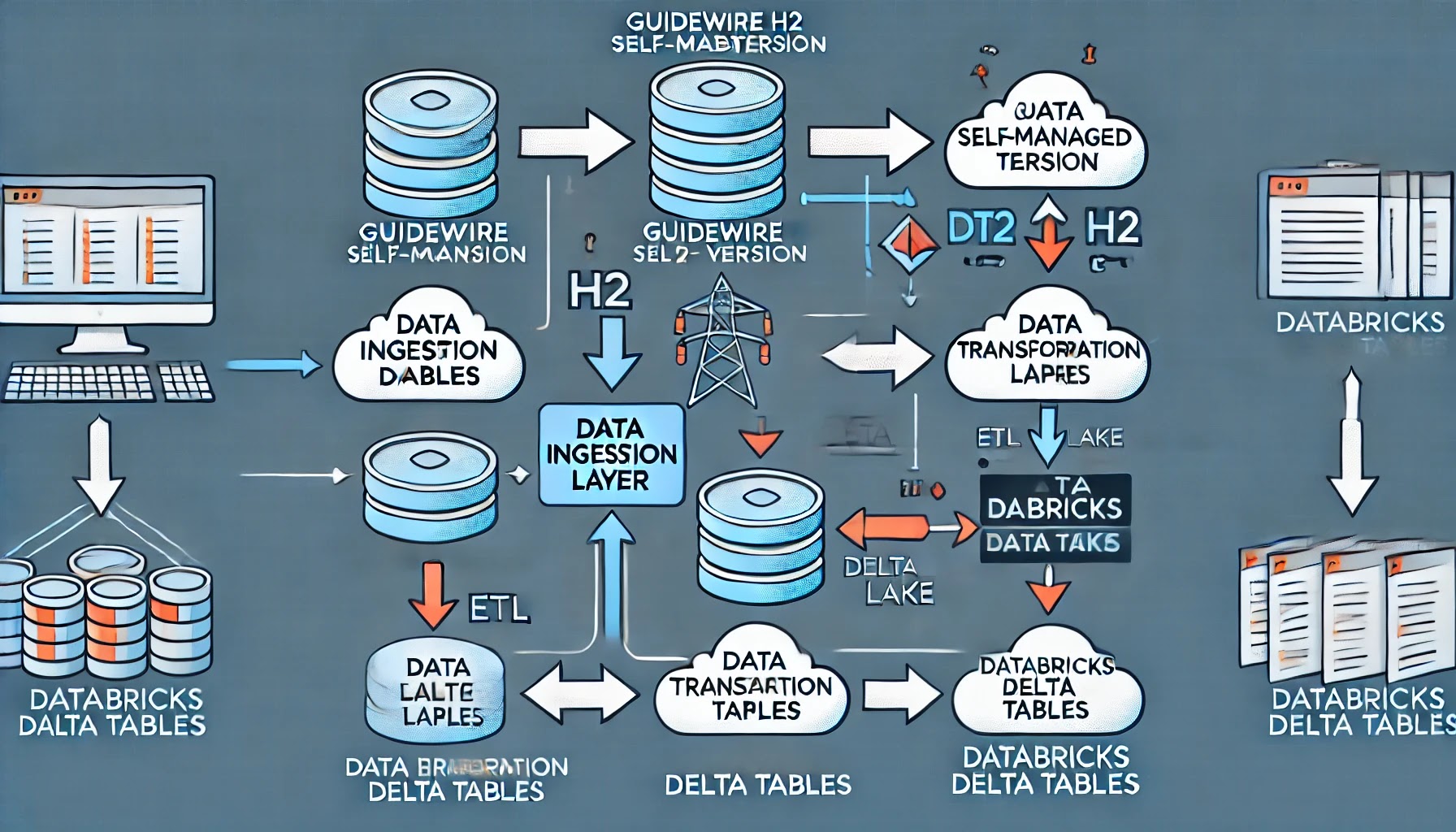
Step 1: Query H2 tables


Step 2: Save Resultsets into CSV files and rename prefix with clm_

Step 3: Upload all these CSV into Databricks Filestore

Click Create Table then Below pop up will open and upload all csv files


Step 4: Check it in Catalog--> FileStores --> All Clm_ prefix files are available !!

Step 5: Ingested CLM_ csv prefix files now it will be created as delta tables in Databricks as well as migrate to new guidewire raw database
PySpark Code has below
import osfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import IntegerTypefrom pyspark.sql.functions import col# Initialize Spark session (usually pre-initialized in Databricks)spark = SparkSession.builder.appName("CreateTablesFromCSV").getOrCreate()# Define the base path for FileStorebase_path = "dbfs:/FileStore/"# Define file prefixes to look forfile_prefixes = ["clm_"]# Iterate over file prefixes and create tables based on file namesfor prefix in file_prefixes:# List all CSV files that start with the given prefix in the FileStorecsv_files = dbutils.fs.ls(base_path)# Filter for CSV files that match the prefixprefix_files = [f.path for f in csv_files if f.name.startswith(prefix) and f.name.endswith(".csv")]# Load each CSV file and create a tablefor file_path in prefix_files:# Extract the table name from the file name (remove ".csv")table_name = os.path.basename(file_path).replace(".csv", "")# Load the CSV file into a DataFramedf = spark.read.format("csv").option("header", "true").load(file_path)# Change the ID column data type from string to Integer, if it existsif 'ID' in df.columns:df = df.withColumn("ID", col("ID").cast(IntegerType()))# Create a table with the same name as the file (without .csv extension)df.write.format("delta").mode("overwrite").saveAsTable(table_name)# Print success messageprint(f"Table '{table_name}' created successfully from file '{file_path}'.")
Table 'clm_cc_claim_h2' created successfully from file 'dbfs:/FileStore/clm_cc_claim_h2.csv'. Table 'clm_cc_contact_h2' created successfully from file 'dbfs:/FileStore/clm_cc_contact_h2.csv'. Table 'clm_cc_credential_h2' created successfully from file 'dbfs:/FileStore/clm_cc_credential_h2.csv'. Table 'clm_cc_group_h2' created successfully from file 'dbfs:/FileStore/clm_cc_group_h2.csv'. Table 'clm_cc_user_h2' created successfully from file 'dbfs:/FileStore/clm_cc_user_h2.csv'. Table 'clm_cctl_claimstate_h2' created successfully from file 'dbfs:/FileStore/clm_cctl_claimstate_h2.csv'. Table 'clm_cctl_grouptype_h2' created successfully from file 'dbfs:/FileStore/clm_cctl_grouptype_h2.csv'.Log info
Table 'clm_cctl_lobcode_h2' created successfully from file 'dbfs:/FileStore/clm_cctl_lobcode_h2.csv'.

Now these tables are available in default database, let's create new database related to guidewire and then move all these clm prefix table into guidewire claim raw table
PySpark Code below for this
from pyspark.sql import SparkSession# Initialize Spark session (usually pre-initialized in Databricks)spark = SparkSession.builder.appName("MoveTablesToNewDatabase").getOrCreate()# Define the new database namenew_database_name = "gw_claims_raw_db"# Step 1: Create a new database (if it doesn't exist)spark.sql(f"CREATE DATABASE IF NOT EXISTS {new_database_name}")# Step 2: List all tables in the default databasedefault_tables = [row.name for row in spark.catalog.listTables('default')]print(f"Tables found in default database: {default_tables}")# Step 3: Copy each table from default database to the new databasefor table_name in default_tables:# Read the table from the default databasedf = spark.table(f"default.{table_name}")# Write the table to the new databasedf.write.format("delta").mode("overwrite").saveAsTable(f"{new_database_name}.{table_name}")# Print success messageprint(f"Table '{table_name}' moved successfully from 'default' to '{new_database_name}'.")
Log message has below
Table 'clm_cctl_lobcode_h2' moved successfully from 'default' to 'gw_claims_raw_db'.

GW Tables Created and Moved to Guidewire Raw Database v1.0 Published
it will be look like this below

This is done with Guidewire Self Managed version
from H2 to CSV tables
from CSV to delta tables in databricks notebook
Finally

Now create new notebook and then exploring guidewire claims raw tables via simple SQL Queries
In Next Blog Post,
will see more Databricks SQL queries for Guidewire Claims Raw Tables and Queries
Additional Notes: It is Guidewire Self-managed version and In Guidewire Cloud we have s3 bucket parquet files and other options like OSS to convert Parquet to csv files !
For enterprise firm versions on Guidewire Cloud it has capabilities like Data Engineer team to load these type csv to delta tables it will be automated where as here we are doing manual process to create csv files
Data science team able to work on ML experiments like databricks environment
Comments
Post a Comment
Share this to your friends